The history of developer tools reveals a consistent pattern: domain-specific solutions inevitably outcompete general-purpose ones. We've seen this play out repeatedly:
Why does this happen? Domain-specific tools can make intelligent tradeoffs that general-purpose tools cannot. For AI coding agents, this translates to specialisation in context, tools and interface.
General-purpose coding agents (e.g., Claude Code, Cline) and IDEs that natively incorporate similar agents (e.g., Cursor, Windsurf) have grown rapidly in capabilities and popularity. These tools focus on exposing raw model performance to users and don't offer domain-specific optimizations or tooling.
In our experience, today's models, and by extension coding agents, are great at tasks represented in benchmarks, such as SWE-bench and Terminal Bench, as well as competitive programming platforms like Leetcode and AtCoder.
However, in our testing results and feedback from experienced developers, even SOTA models struggle with real-world frontend tasks, such as building a large component or page using a component library and tech stack while adhering to frontend best practices. In our evaluation of large frontend tasks across different stacks, SOTA models failed to produce compilable code 30-40% of the time, even when coupled with best-in-class agents and MCPs. Their performance on code quality and feature implementation also lags significantly behind their results on public benchmarks. (see details)
This discrepancy is not surprising, as existing coding benchmarks rarely feature complex frontend tasks. For example, 90%+ of issues on SWE-bench are simple bug fixes (source, see the graph below).
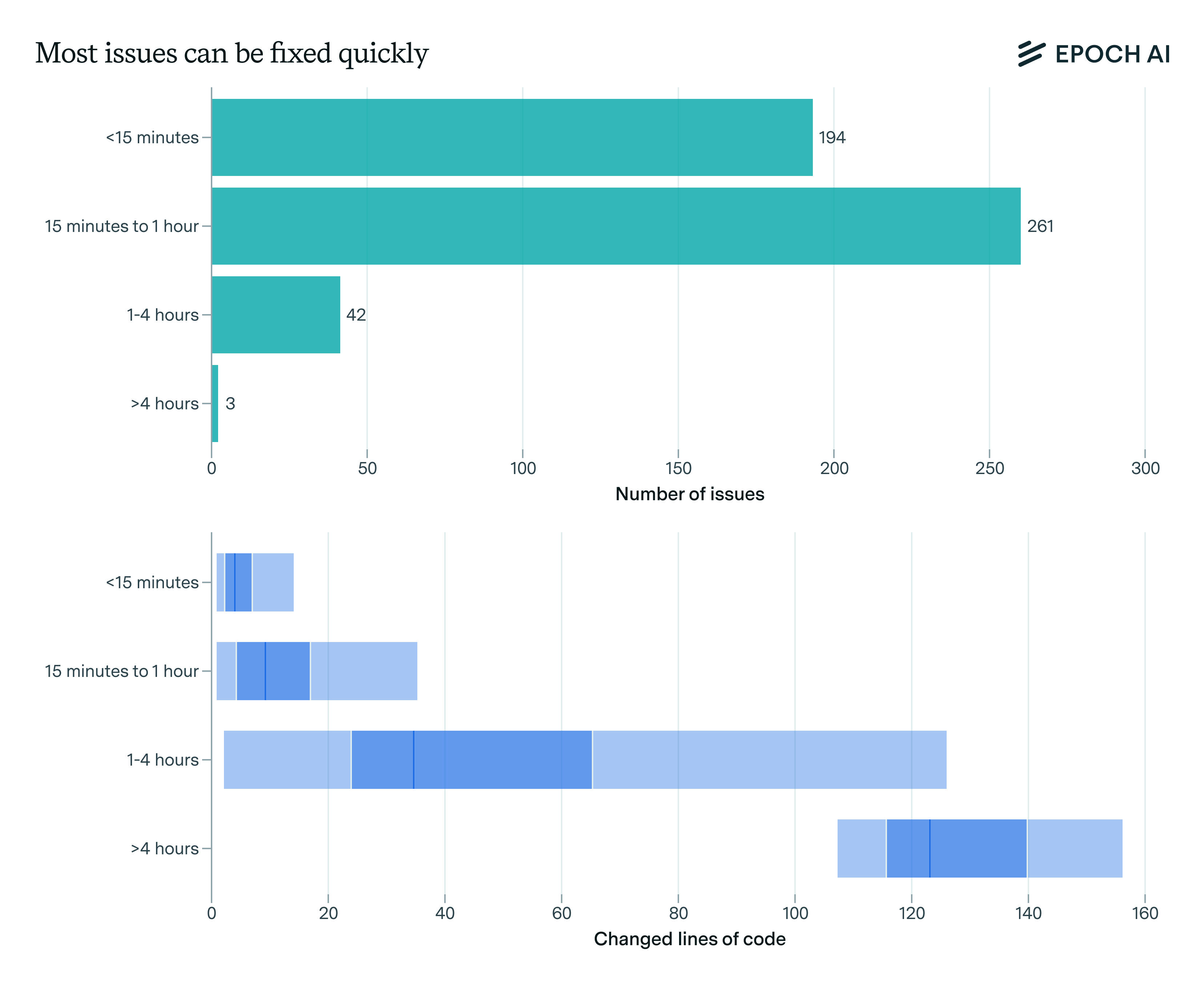
Distribution of time taken to solve SWE-bench issues. Source: Epoch AI
While some expert developers have managed to make these general-purpose agents work through extensive context engineering, most developers are not LLM experts and are unable to leverage these tools for their complex tasks.
This highlights a critical need for a frontend-specific agent capable of handling the intricate tasks developers face daily.
Kombai's agentic capabilities are purpose-built for frontend tasks. This singular focus allows us to make opinionated decisions that are impractical for general-purpose coding agents. Our optimizations can be broadly categorized into two areas: context engineering and tooling.
Existing coding agents typically use model APIs to generate embeddings for code snippets and documents, followed by embedding search APIs (such as Pinecone) to find relevant matches. While effective for text or code snippet similarity, this approach often misses crucial domain-specific context, such as which components to use for a given task. This leads to insufficient accuracy and high latency for real-world frontend tasks.
Kombai adopts a more human-like method to understand a codebase. It first identifies the key parameters needed for writing high-quality code within a given repository and then extracts the necessary information, such as code files and configurations. For example, in a codebase with a custom component library, Kombai tries to understand each reusable component's function, UI appearance, and required props—much like a human developer onboarding to a new codebase.
Using best practices from relevant libraries is crucial for production-ready frontend code. Current agents rely on documentation MCPs (often model-generated extracts) that can be unreliable and fail to account for common pitfalls specific models run into. While some developers create extensive, agent-specific rules, maintaining these is effort-intensive given the rapid evolution of models, MCPs, and libraries.
Kombai, on the other hand, has built-in, human-tested context tools for each supported frontend library. These tools provide models with up-to-date, version-specific best practices, including guidance for popular library combinations (e.g., using a specific component library with a particular styling framework).
For many professional frontend teams, Figma files are the primary source of design instructions. Developers currently use image exports or Figma MCPs with existing agents, which often struggle with complex, real-world designs. These MCPs can also be context-inefficient, leading to model hallucinations.
Kombai's Figma interpretation engine goes beyond simple data fetching. It understands Figma designs like a human, accounting for common "non-ideal" patterns such as incorrect grouping, unintended layers (invisible elements, overlapping nodes), or accidental fills/shadows. This engine is an evolution of our popular Figma-to-code model, which was Product Hunt's top developer tool of 2023. (link)
General-purpose agents typically lack domain-specific tooling. Kombai, on the other hand, has built-in specialized tools to enhance model performance for frontend tasks.
For complex tasks, Kombai generates a detailed plan that is domain-specific and task-aware. For an application-related task, this plan might include schemas, enums, and endpoints, while for a marketing landing page, it would focus on color schemes, fonts, and animations. In addition, it also includes the sections and features Kombai plans to build.
All plan files are generated as editable markdown files. They can also be updated by natural-language prompts via chat.
After code generation, Kombai automatically attempts to fix all linting and TypeScript errors. It also includes workflows for users to easily send runtime errors to the agent from their browsers.
Kombai does not write to a user's local codebase until the generated code is explicitly saved. This allows for safe and easy iteration without the risk of unintended or difficult-to-revert changes.
Once the code is validated, Kombai can run a sandbox server to provide a visual preview of the generated output. This is vital for large frontend tasks where developers often rely on browser previews to understand and debug the code—from styling to functionalities.
LLM models from major providers evolve rapidly, and their benchmarks often don't represent real-world frontend tasks. Discovering the best model for a given job is often time- and cost-intensive.
We continuously benchmark the latest frontier models to understand their capabilities and limitations on various frontend tasks. Based on our proprietary, regularly updated benchmarks, Kombai's agent selects the most suitable model for a given task, saving developers the time and expense of discovering this themselves.
Automated performance evaluation, aka "running evals" or benchmarking, is crucial for measuring and improving agent performance.
Given the lack of available benchmarks for real-world frontend tasks, we had to build our own test set of over 200 real-world tasks. This set includes various Figma designs and text instructions to be coded across different frontend tech stacks.
📋 We've open-sourced the dataset at kombai-io/benchmark-prompts
We defined three criteria for this evaluation:
Do the code outputs compile cleanly without errors? (Measured by running the code and checking for compilation errors.)
Do the code outputs adhere to a defined set of frontend coding best practices?
This was evaluated by an LLM-as-a-judge approach, scoring outputs on a 0-5 scale
Example Criteria
Separate API/data logic from UI
Clear separation of concerns and code organization
No repeated markup or logic—use reusable components or utilities
Do the outputs include the expected visual and functional features?
This was also evaluated by an LLM-as-a-judge that first generates expected features, then scores the code/screenshots against them. The functional features were judged from code, while the visual features were judged based on screenshots of the final output. For tasks where user action is necessary to get a meaningful screenshot (e.g., a modal that opens on a button click), we provided the model-judge with a post-action screenshot.
Example Criteria
The "Sort by" dropdown should immediately reorder only the product cards within the currently visible category. (functional)
In the "People you may know" carousel, clicking the "Connect" button should immediately change it to a disabled "Pending" state, without affecting any other cards. (functional)
A slim, full-width promo bar must appear at the very top of the page, containing three text segments: a discount offer on the left, an address with a "change location" option in the center, and a cart summary on the right; in the main navigation, the "Restaurants" link must be styled as the active tab, highlighted with an orange rounded underline or pill. (visual)
A vertically stacked thumbnail strip with four equally sized square images must appear flush left of the main product photo, with consistent spacing between them, and the currently selected thumbnail highlighted by a thin green border. (visual)
We evaluated Kombai against the current state-of-the-art for agentic coding using Claude Sonnet 4 and Gemini 2.5 Pro.
For general-purpose agentic tasks, we used Aider (without MCP) and OpenAI agents SDK + CodeMCP (with Sonnet) or Filesystems MCP (with Gemini). All agents were allowed three attempts to fix errors, with relevant error messages provided as context.
Context7 MCP was used for documentation and Framelink MCP for Figma designs. O3 was used for the LLM-as-a-judge evaluations due to its reasoning abilities. All code generations were run programmatically.
Kombai consistently outperformed general-purpose agents across all three evaluation categories.

It's perhaps not surprising that a domain-specific agent excels in its area of specialization. However, given the rarity of such agents, these results serve as validation of our domain-specific approach.
To be sure, this exercise is not a critique of SOTA models or general-purpose coding agents. Kombai utilizes various SOTA models, and we are impressed by their rapid, cross-domain improvements. Rather, this demonstrates that by building on the strengths of these models with agentic optimizations, we can deliver significant improvements in domain-specific performance.
Going forward, we'd like to improve the robustness of our evals and use them regularly to guide our development roadmap. Some of the known improvement areas are as follows:
Using multiple SOTA models as judges and averaging their scores.
Increasing our sample size to include more tech stack variations.
Adding test tasks that involve working with existing codebases.
Incorporating statistically designed human evaluations alongside the LLM-as-a-judge approach.
We are grateful to all the users who gave us a try during our private alpha and helped us shape the product with invaluable feedback.
Our journey of building the domain-specific frontend agent has just started. We have an exciting roadmap ahead, including support for more frameworks and libraries, task-specific agents, optimizing token efficiency, and UX improvements. We will keep building rapidly and release new updates frequently.
We are actively seeking feedback from our early adopters. So if you have any feedback on what we need to build or improve next, please don't hesitate to reach out to us via socials (X, LinkedIn) or email (support@kombai.com).